All’università circolano molte fotocopie tra libri e appunti, c’è molto materiale che viene fotocopiato diverse volte. Non è insolito avere a che fare con fotocopie poco leggibili, anche in grandi volumi, su cui bisogna spendere molte ore di studio.
Come se non bastasse, in facoltà abbiamo una copisteria privata che si occupa di raccogliere tutte le dispense dei professori per poi vendere le copie agli studenti. Invece di affidare a terzi questo volume di materiale, si potrebbe creare una sezione sul sito web dell’università dedicata al download di tale materiale. Invece sei costretto a mobilitarti, recarti in facoltà, prendere il turno per prenotare le fotocopie e attendere che le stampino. In realtà c’è una sorta di sezione download per i corsi, ma quasi nessun professore la utilizza, ma questa è un’altra storia.
Mi capita quando studio fuori casa di aver bisogno di alcune dispense che non sono con me, perché le dimentico a casa oppure le presto in giro. Per evitare di ritrovarmi in questa situazione ho cercato di scannerizzare le diepense, per poi portarle con me sulla penna usb. Ma i file che ottenevo erano esageratamente grandi, e la loro pesantezza rendeva goffa la consultazione con un lettore pdf.
Preso atto di questo mi sono rimboccato le maniche per sapere come fare delle buone scansioni, che occupassero poco spazio su disco e al tempo stesso conservando una ottima leggibilità. Riuscendo dove è possibile, a migliorare anche la resa visiva.
Il processo di scansione
Lo scanner che uso è quello di una stampante multiuso, ha la particolarità di avere il doc feeder, così non devo aprire il piano e rieseguire le scansioni. Il software in dotazione con lo scanner fa schifo, è la prima cosa che ho messo da parte. I motivi sono la velocità di scansione e l’alterazione dei colori.
Se siete su Windows vi consiglio di procurarvi vue scan, riesce a compiere un buon lavoro senza troppe pretese, per GNU/linux potete sempre rivolgervi a sane.
La risoluzione di scansione che ho impostata è dannatamente alta: 600dpi. Serve soprattutto per lavorare con i contorni dei caratteri, una media-bassa risoluzione rischierebbe di creare una marmellata di pixel.
Per velocizzare l’acquisizione seleziono una scansione in scala grigi, ma per qualche motivo il software si ostina a creare una immagine a colori molto sbiaditi. Questo poi lo correggerò nel filtraggio dell’immagine utilizzando ImageMagick, un ottimo prodotto a riga di comando che può lavorare su grandi quantità di file.
Visto che solitamente le fotocopie sono in bianco e nero, cercherò di filtrare le immagini per renderle tali risparmiando spazio su disco.
I difetti delle fotocopie
Ci sono principalmente due tipi di dispense fotocopiate, quelli scritte al computer e quelli redatti a mano. Ognuno ha un tipo di problemi da affrontare che si risolvono piuttosto semplicemente con lo stesso metodo.
Solitamente gli appunti si prendono su pagine a righe oppure a quadri, l’ideale sarebbe eliminarle e lasciare solo il testo che interessa a noi. Si risparmia inchiostro nella stampa e si ottengono immagini più pulite. Alcune persone usano anche l’evidenziatore e circondano il testo con riquadri colorati.
Fortunatamente abbiamo accesso agli originali per quanto riguarda gli appunti dei colleghi, e non abbiamo a che fare con brutte fotocopie della copisteria riciclate chissà quante volte. Spesso sono sporche e deformate perché durante la scansione non si tiene il foglio perfettamente fermo, e i rulli della fotocopiatrice imbrattano ulteriormente il foglio. Questo a lungo andare rende i caratteri sempre meno leggibili.
Trattamento
Il nostro obiettivo è ottenere immagini nitide in bianco e nero, il più possibile pulite. Per bianco e nero si intende immagini composte da due soli colori; appunto bianco e nero. La scala grigi non è contemplata, così facendo riduciamo enormemente lo spazio occupato sul disco.
Uso principalmente due parametri per ImageMagick, gaussian-blur e threshold. Il primo serve a sfocare l’immagine leggermente mentre il secondo serve per dare un taglio netto ai colori passando tutto in bianco e nero. Occasionalmente utilizzo anche il contrasto per rimuovere le righe dagli appunti. Per esempio con questo comando otteniamo:
convert -colorspace gray +contrast +contrast prima.tif dopo.tif

Ora dobbiamo rendere tutto in bianco e nero, se utilizziamo direttamente la soglia i contorni dei caratteri risulteranno troppo seghettati e non regolari. Possiamo in un certo senso ammorbidire l’immagine con la sfocatura gaussiana e poi filtrare il tutto con la soglia, in questo modo grazie all’alta risoluzione rendiamo morbidi i contorni che risulteranno più regolari.
convert -gaussian-blu 3.0 threshold 90% prima.tif dopo.tif
Di seguito potete vedere l’immagine a sinistra senza l’opzione –gaussian-blur, mentre a destra quella con l’opzione abilitata.
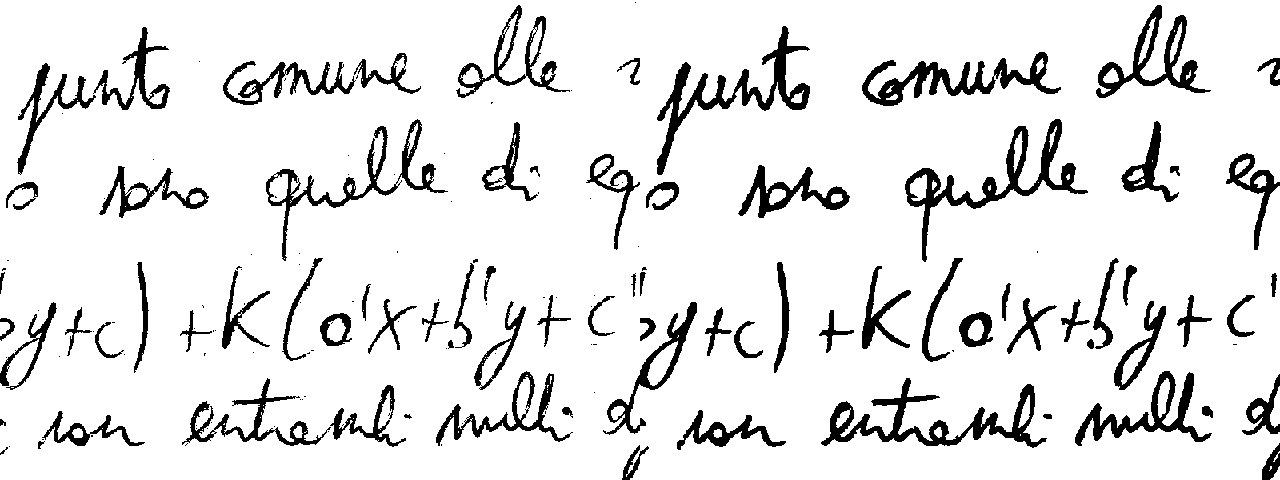
In realtà possiamo eliminare le righe semplicemente ignorandole, la sfocatura e la soglia elimineranno anche quelle dall’immagine.
Il colore dell’evidenziatore e i riquadri colorati vanno trattati allo stesso modo, basta saper giocare con i giusti valori. Eccezionalmente possiamo trattare le singole immagini con un editor come the gimp se il lavoro è poco.
Questo è un esempio di testo dentro un riquadro e dei vari tentativi che si possono fare per rendere chiara e pulita l’immagine.

Le macchie minori e il colore dominante vanno via, perché rese “deboli” dalla sfumatura e poi scartate dalla soglia. Quello che otteniamo è una buona copia delle nostre fotocopie, ottenete delle immagini perfettamente bianco e nero e nella stampa non verrà sprecato inchiostro.
Automatizzare il tutto
Ora che abbiamo trovato la nostra combinazione di opzioni andiamo ad automatizzare il tutto, possiamo anche utilizzare solo ImageMagick dal terminale per processare le pagine dei nostri appunti, oppure usare un piccolo script per fare anche alcune operazioni di conversione finale in DJVU.
Il formato DJVU potrebbe essere inteso come il PDF degli scanrip. Mentre il PDF per conservare le pagine non fa altro che memorizzare una immagine in formato PNG o jpg/jpg2000 a prescindere del contenuto, il formato DJVU scompone la pagina e impiega particolari algoritmi che separano le figure dal testo. Quest’ultimo viene anch’esso scomposto in immagini più piccole, in piccole unità (solitamente i caratteri) che andranno ad essere riutilizzati per tutto il foglio. Questa tecnica permette di avere una pagina pressoché identica all’immagine filtrata ma infinitamente più piccola, siamo nell’ordine di qualche KB. Possiamo avere tutte le nostre dispense su disco in qualche MB!
Ho scritto un piccolo programma in python che prende l’immagine originale, la filtra e la converte in DJVU tutto tramite ImageMagick e la suite djvulibre. Alla fine del processo ho un unico DJVU pronto da mettere su penna usb. Si assume che le immagini abbiamo un nome sequenziale, qualcosa del tipo scan01.tif, scan02.tif e così via e che siano raccolte in due gruppi, latoA e latoB.
import os somma=" " npagine = 100 for x in range(npagine): a = 'latoA%03d' % x os.system('convert -colorspace gray -gaussian-blur 3.0 -threshold 90% originali/%s.tif filtrati/%s.tif' %(a,a)) os.system('cjb2 -dpi 600 -verbose -lossy filtrati/%s.tif %s.djvu' % (a,a)) a = a+'.djvu ' b = 'latoB%03d' % x os.system('convert -colorspace gray -gaussian-blur 3.0 -threshold 90% originali/%s.tif filtrati/%s.tif' %(b,b)) os.system('cjb2 -dpi 600 -verbose -lossy filtrati/%s.tif %s.djvu' % (b,b)) b = b+'.djvu ' somma = somma + a + b os.system('djvm -c scansione.djvu ' + somma)
Come si vede dallo script eseguo prima il filtraggio, dopo converto in DJVU e copio il nome dentro una variabile. A fine ciclo eseguo DJVM che crea il mio file finale. Può sembrare macchinoso all’inizio, ma il procedimento regala ottimi risultati.